

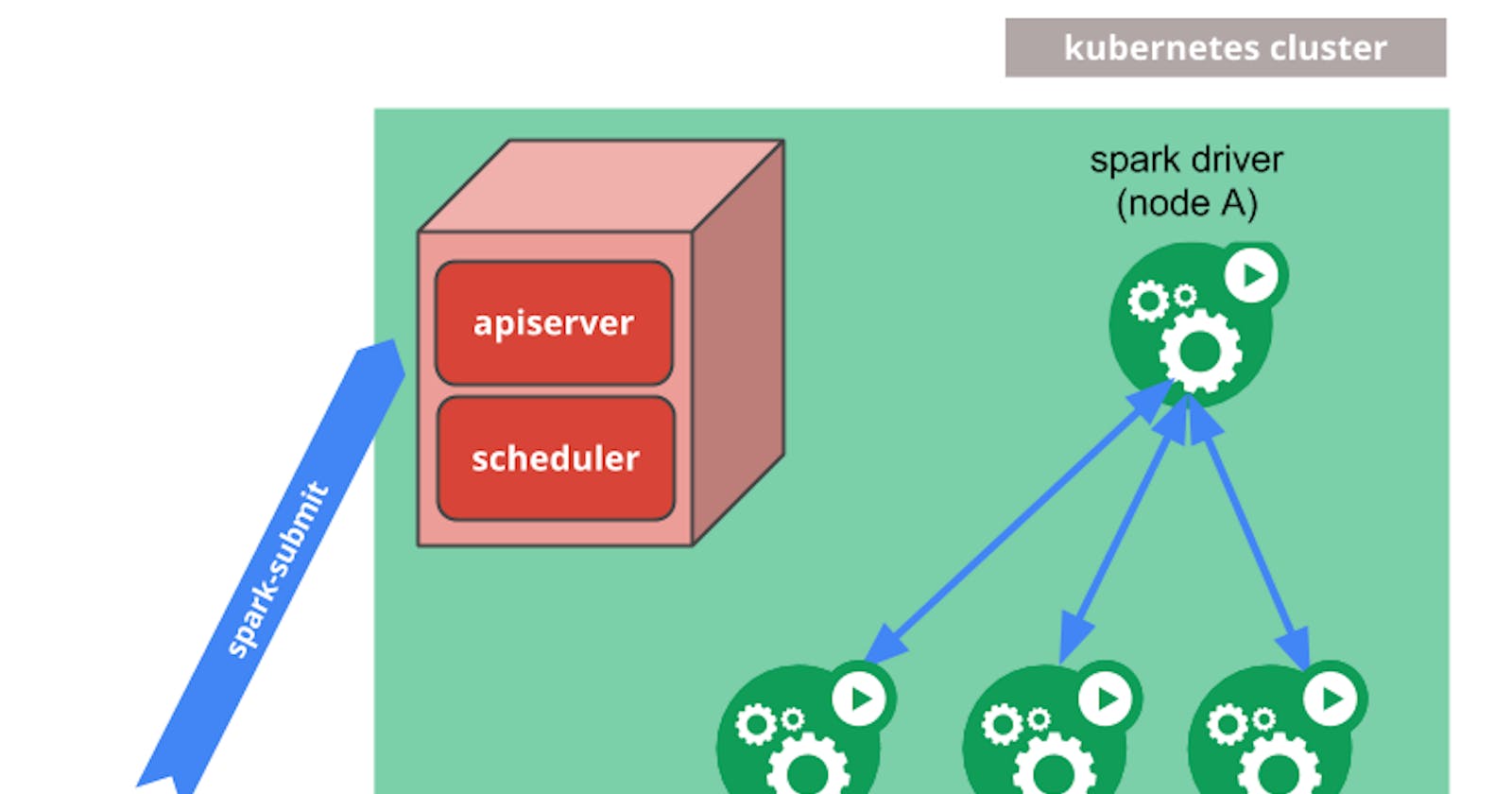
Spark on Kubernetes with Helm and Docker Desktop
A guide on installing a Spark cluster using Helm onto Docker Desktop's local Kubernetes cluster and how to spark-submit PySpark scripts to it


Prerequisites
Docker Desktop v4.25.2
Kubernetes v1.28.2
Helm v3.13.2
Installation and Setup
Download the bitnami Helm repository:
helm repo add bitnami https://charts.bitnami.com/bitnami
Install the bitnami/spark Helm Chart into the docker-desktop Kubernetes cluster:
helm upgrade --install spark bitnami/spark --create-namespace --namespace ns-spark
helm upgrade command installs the chart and creates the necessary pods, services and service accounts within the namespace ns-spark for Spark to run. The pods run as a service account named "spark" because that's what we've named the Helm release.Run the k9s command to see the local Kubernetes cluster:
k9s
You should see something like this:

# god mode "spark" service account
kubectl create rolebinding godmode \
--clusterrole=cluster-admin \
--serviceaccount=system:ns-spark:spark \
--namespace=ns-spark
Now that the Spark Cluster is installed, run the kubectl proxy command in a new terminal window:
kubectl proxy
And then access the Spark Master Web UI using the following URL:
http://localhost:8001/api/v1/namespaces/ns-spark/services/http:spark-master-svc:http/proxy/
You should see something like this:

Hooray 🚀 Spark is now installed on your local Kubernetes cluster.
Submit PySpark Jobs with spark-submit
Now that the Spark Cluster is installed, let's submit a Spark job to it.
Create a simple PySpark script and save it as test.py on your local machine:
import pyspark
import random
import time
spark = pyspark.sql.SparkSession.builder.appName('myPySparkApp').getOrCreate()
sc = spark.sparkContext
num_samples = 100
def inside(p):
print('hello world from PySpark')
time.sleep(10)
x, y = random.random(), random.random()
return x*x + y*y < 1
count = sc.parallelize(range(0, num_samples)).filter(inside).count()
pi = 4 * count / num_samples
print(pi)
sc.stop()
spark-submit command without installing Spark directly onto your machine is to use it from inside an ephemeral container with Spark installed, running in the k8s cluster.Run a Spark container using the official Apache Spark docker image in k8s with this command:
kubectl run --namespace ns-spark \
spark-ephemeral --rm --tty -i \
--image docker.io/spark:3.5.0-scala2.12-java17-python3-ubuntu \
--overrides='{"apiVersion":"v1","spec":{"serviceAccount":"spark","serviceAccountName":"spark"}}' \
-- bash
You should now be inside the terminal of the running ephemeral container:

Within the container terminal, run this command to run test.py using spark-submit:
/opt/spark/bin/spark-submit \
--conf spark.executor.cores=1 \
--conf spark.executor.memory=500M \
--conf spark.driver.cores=1 \
--conf spark.driver.memory=500M \
--conf spark.executor.memoryOverhead=500M \
--class org.apache.spark.examples.SparkPi \
--name spark-pi \
--deploy-mode cluster \
--conf spark.kubernetes.container.image=docker.io/spark:3.5.0-scala2.12-java17-python3-ubuntu \
--master k8s://https://$KUBERNETES_SERVICE_HOST:$KUBERNETES_SERVICE_PORT_HTTPS \
--conf spark.kubernetes.driverEnv.SPARK_MASTER_URL=spark://$KUBERNETES_SERVICE_HOST:$KUBERNETES_SERVICE_PORT_HTTPS \
--conf spark.executor.instances=4 \
--conf spark.kubernetes.namespace=ns-spark \
--conf spark.kubernetes.authenticate.driver.serviceAccountName=spark \
--conf spark.kubernetes.driver.volumes.hostPath.<VOLUME NAME>.mount.path=<PATH IN CONTAINER> \
--conf spark.kubernetes.driver.volumes.hostPath.<VOLUME NAME>.mount.readOnly=true \
--conf spark.kubernetes.driver.volumes.hostPath.<VOLUME NAME>.options.path=<YOUR LOCAL DIR PATH> \
--conf spark.kubernetes.executor.volumes.hostPath.<VOLUME NAME>.mount.path=<PATH IN CONTAINER> \
--conf spark.kubernetes.executor.volumes.hostPath.<VOLUME NAME>.mount.readOnly=true \
--conf spark.kubernetes.executor.volumes.hostPath.<VOLUME NAME>.options.path=<YOUR LOCAL DIR PATH> \
local:<PATH IN CONTAINER>/<SCRIPT NAME>
--conf spark.kubernetes.driver.volumes.hostPath.<VOLUME NAME>.options.path=<YOUR LOCAL DIR PATH> could be --conf spark.kubernetes.driver.volumes.hostPath.mylocalfolder.options.path=/Users/FirstName.LastName/Documents/MyCode/. More information about Spark and Kubernetes Volumes can be found here.Inside K9s, you should see the Spark driver and executor pods running:

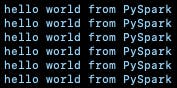
If you observe the logs of one of the executor pods, you'll see that test.py is running:
To uninstall Spark, including associated service accounts, run this command:
helm delete spark --namespace ns-spark
You have successfully submitted a PySpark job to a Spark cluster running in Kubernetes 🚀